Google and Facebook spend a lot of money on AI. We don’t have specific numbers, but we know Google increased its overall R&D spend from $27.6bn in 2020 to $31.6bn in 2021 and Facebook from $18.4bn to $24.7bn. Facebook recently announced the development of the world’s largest AI supercomputer called RSC or Research Super Computer. Google’s AI program is so advanced that a senior Google engineer recently pronounced it sentient. While all of that is anecdotal, it is reasonable to assume Google and Facebook have invested substantial sums into developing machine learning resources that leverage your data to better understand you; what you are interested in and what you are likely to buy. After all, you are their product so it makes sense for them to want to get to know you.
We should use our data to learn more about ourselves.
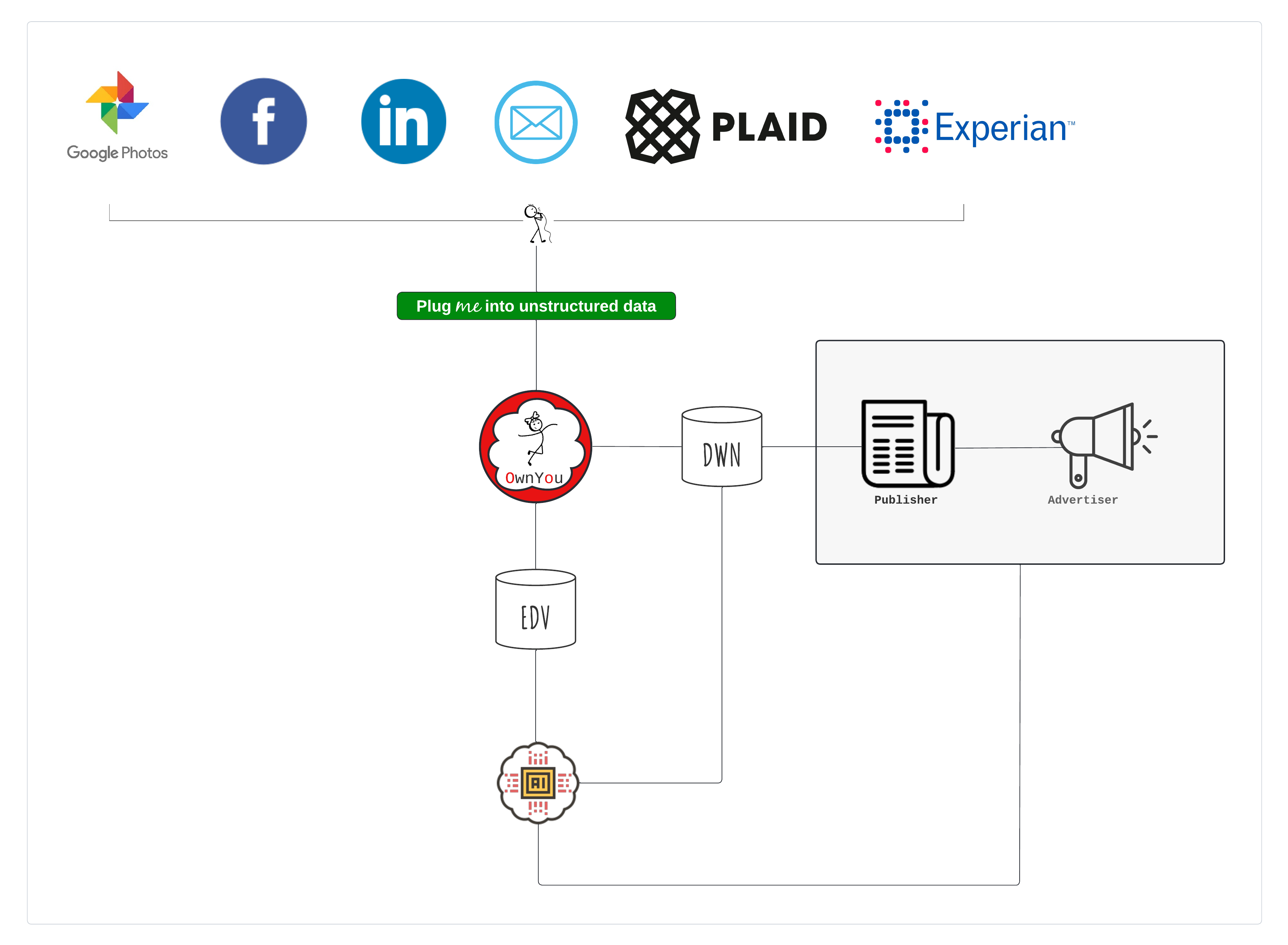
OwnYou suggests we use our personal data to build our own unbiased consumer profiles, and we should profit from them in the same way Google, Microsoft, Apple and Facebook profit from them. Except in our case, we own the data, and we control the process. This is a non-trivial endeavour mostly because users should never share unencrypted data. Instead we need to make encrypted user data available to the intelligence stack, a community of data scientists, while maintaining user privacy, and receive target audience data, and other consumer profiles, in return.
We need to compensate data scientists according to the quality of their work and accuracy of their predictions. There are many moving parts. We need to collect personal data from third parties (social media, email, financial records, credit rating agencies etc). Individuals need to store that data in a secure location, ideally (perhaps eventually) without relying on centrally managed data storage providers, with the data always encrypted (at rest and in transit). We need facilitate machine learning while never sacrificing user privacy. The intelligence stack needs to be able to build useful models and then apply those models to encrypted data. Individuals need to be able to use that data and the intelligence stack needs to be compensated fairly and in accordance with the value they provide advertisers.
Frameworks
OwnYou will use one or more promising privacy preserving machine learning (ML) frameworks including homomorphic encryption, federated learning , differential privacy and multiparty computation. While privacy preserving computation (PPC) is an increasingly well researched field, OwnYou has the following constraints:
- Many sources of data: unlike most privacy preserving problems where the data is in one, or perhaps a few, locations, our data is spread across millions, potentially billions, of different user Encrypted Data Vaults (EDVs). We do not want to centralize data. We are not seeking a data union which we think carries too greater attack surface. EDVs will leverage decentralised storage networks, using content addressing. How can encrypted distributed decentralised data, with complex user driven access controls, be used for machine learning training and inference?
- Many machine learning actors accessing many sources of data at the same time. The richer and more diverse the set of machine leaning actors, the more likely we extract the maximum value from individual user data. This benefits the user, advertisers, and the community of machine learning actors.
- Some machine learning frameworks will rely on remote computing resources, where models are run on local data. This necessitates decentralised compute resources.
- We need to be mindful of redundancy. The community does not benefit from thousands of ML actors running the same algorithms over the same data with the same result. One approach might be to develop a shared training data set that ML actors can run locally. Target thresholds could be required before an algorithm can be trained on the broader decentralised user data, with further thresholds before they can be used for inference.
- The ML effort should be competitive. ML actors should be required to earn the right to service users with a particular algorithm.
- Target audience recommendations should be delivered with measure of likely accuracy. Those predictions should be measured against actual user behaviour, and advertiser returns on advertising spend (ROAS). Machine leaning actor compensation should be tied to ROAS.
Federated learning holds the most promise.
Federated learning (FL) is a machine framework where many clients (for instance mobile devices or user encrypted data vaults), collaboratively train a model under the control of a centrally managed service provider. Sensitive private data need never leave local user control. All computation is carried out locally. Research has also proposed a framework for decentralised federated learning where the data itself is stored on IPFS. TensorFlow Federated (TFF) is an open-source framework for machine learning and other computations on decentralised data. TFF has been used to train prediction models for mobile keyboards without uploading sensitive tying data to servers.
